Emphasis: 以下内容全是通过个人理解整理所得,如有错误,欢迎指出。
**版权所有:杨苏辉**
第一章
本章主要从Reinforcement learning(RL)基本概念出发,介绍传统强化学习的一些经典算法并辅以公式推导和程序实现。
RL基本概念
在经典强化学习中,智能体要和环境完成一系列交互:
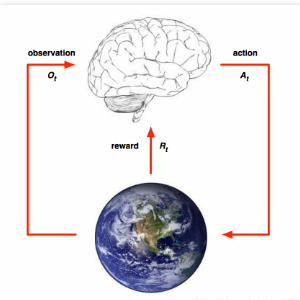
(4)这个行动会影响环境的状态,是环境发生一定的改变。Agent将从改变后的环境中得到两部分信息:新的环境观测值和行为给出的回报。Agent可以根据新的观测值做出新的行动。
DRL vs DL





DRL项目搭建流程(PIPELINE)








DRL examples



更多应用场景:
自动驾驶: 自动驾驶载具(self-driving vehicle)
控制论(离散和连续大动作空间): 玩具直升机、Gymm_cotrol物理部件控制、机器人行走、机械臂控制。
游戏: Go, Atari 2600(DeepMind论文详解)等
理解机器学习: 自然语言识别和处理, 文本序列预测
超参数学习: 神经网络参数自动设计
问答系统: 对话系统
推荐系统: 阿里巴巴黄皮书(商品推荐),广告投放。
智能电网: 电网负荷调试, 调度等
通信网络: 动态路由, 流量分配等
物理化学实验: 定量实验,核素碰撞,粒子束流调试等
程序学习和网络安全: 网络攻防等
第一课作业:
下图中根据每个人自己的理解对human life进行抽象,得到Goal、State、Actions、Reward指标。

keypoints




简化模型及MDP
RL模型简化

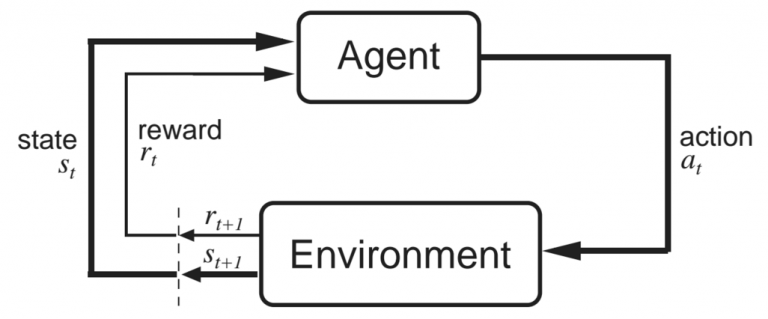
来自Sutton和Barto的书“Reinforcement Learning: an Introduction”(这是强烈推荐的)的这张图,很好的解释了智能体和环境之间的相互作用。在某个时间步t,智能体处于状态s_t,采取动作a_t。然后环境会返回一个新的状态s_t+1和一个奖励r_t+1。奖励处于t+1时间步是因为它是由环境在t+1的状态s_t+1返回的,因此让它们两个保持一致更加合理(如上图所示)。
MDP模型
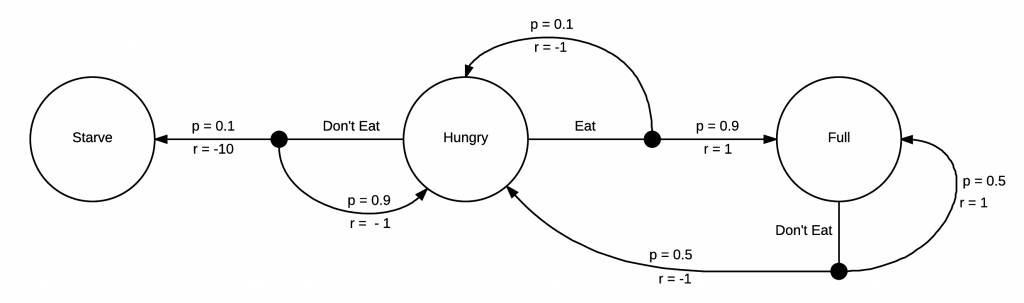
你不需要一个MDP来告诉自己饿了要吃饭,但是强化学习的机制是需要它的。这个MDP增加了奖励机制,你每转化到一个状态,就会获得一次奖励。在这个例子中,由于接下来状态是饥饿,你会得到一个负面的奖励,如果接下来状态是饿死,那会得到一个更负面的奖励。如果你吃饱了,就会获得一个正面的奖励。现在我们的MDP已经完全成型,我们可以开始思考如何采取行动去获取能获得的最高奖励。由于这个MDP是十分简单的,我们很容易发现待在一个更高奖励的区域的方式,即当我们饥饿的时候就吃。在这个模型中,当我们处于吃饱状态的时候没有太多其它的选择,但是我们将会不可避免的再次饥饿,然后立马选择进食。强化学习感兴趣的问题其实具有更大更复杂的马尔科夫决策过程,并且在我们开始实际探索前,我们通常不知道这些策略。
百度百科对马尔可夫链和决策过程的解释:


举个例子,一个抛物线小球,给出当前时刻的速度和位置(当前时刻的状态),下一时刻的小球位置只取觉与当前时刻的小球状态;但是如果只给出当前时刻小球的位置,则下一时刻小球的位置取决于之前所有时刻小球的状态,这时候不具有马尔可夫性质。


我们现在已经有一个强化学习问题的框架,接下来准备学习如何最大化奖励函数。在下一部分中,我们将进一步学习状态价值(state value)函数和状态-动作价值(action value)函数,以及奠定了强化学习算法基础的贝尔曼(Bellman)方程,并进一步探索一些简单而有效的动态规划解决方案。
Bellman Equation优化
推导方式一:


推导方式二:




同一个状态state下同一策略输出的动作不一定是确定的,(例如石头剪刀布中最优策略是随机策略),因此在Bellman Equation推导过程中一定注意每一个变量自身又是一个随机变量;同时即使在同一个状态state下根据一个最优的确定性策略输出确定性动作,得到的下一个state也不一定是唯一确定的,这里会有一个状态转移概率(因此在这里会有确定性环境和不确定环境之分,不确定环境就是同一s,a下一个s不确定)。
臆想场景:
策略是一个战略方针,不是具体的战术动作,例如”敌进我退敌驻我扰敌疲我打敌退我追”16字方针就是一个策略,具体的战术动作需要根据当前所处的状态决定;
1、行军打战到某处,例如灌木从,此时可以有前哨兵勘测地形和敌军状态,例如离我军多远,装备如何,人数,是否是王牌部队等等,继而根据16字方针决定接下来我军的作战策略,是打,是跑还是什么,这个16字方针就可以看作是与敌军不断流血斗争中学到的最优策略;
2、同一个时间,同一个地点,男生向女生表白,得到的下一个状态可能是被拒绝也有可能是接受;即同一个s,a,下一个状态不一定是确定的;
3、石头剪刀布中面对对方出布,我方最优策略是随机策略,即三个动作概率是一样的,不然随着游戏的进行,有所偏重的动作就会被针对,一定是很多局;
4、on-off policy例子,为什么比你高,壮的人,本能是不与之打架,这就是off policy,自己的不打的动作来源于其他人的policy,即其他人打架的与环境的交互行为(结果被暴揍)和自身更新policy不是一个policy;on-policy就是自己不信邪,非要以身尝试,不停的打架最后发现打不过不打了。
算法归纳
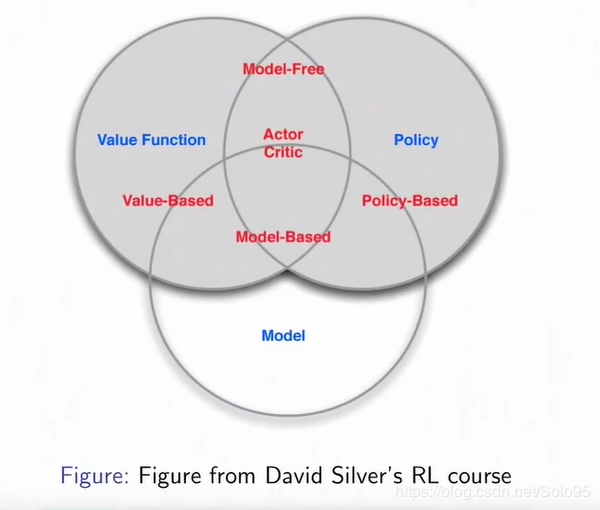
Model-based models
基于model的方法是指环境信息可以获取,例如环境状态转移概率等信息,与之对应的是model-free的方法,该类方法无法获取环境的准确信息,例如无法直接获取环境的状态转移概率;
对于贝尔曼方程的求解,可以采取动态规划(Dynamic Programming)的方法。具体来说,动态规划有两个方法: 这里主要介绍两个model-based的方法,包括值迭代和策略迭代方法。
Value Iteration
算法主要流程如下:

环境:

值迭代函数:

策略policy获取:

Policy Iteration
算法主要流程如下:



不管是值迭代还是策略迭代,都是需要计算出最优的值函数,然后通过值函数计算出Q函数,然后根据Q函数计算出每个状态state下的最优动作action。
Model-free models
很多情况下,环境的模型是未知的,我们不清楚状态之间如何转移,回报的概率是多少,甚至不清楚全部的状态空间长什么样子。这种情况下,如果不采用model-based方法(即,对复杂环境进行建模,建模过程其实就是学习过程,模型建的充分了,智能体对环境就理解充分了,就可以得出最优policy),而是采用model-free的方法(不去对环境进行建模,只用采样的方式学习出一个最优policy),最经典的就是蒙特卡罗算法了。
Monte Carlo(MC) Methods



Temporal Difference(TD(lambda)) Methods

时间差分(TD)方法主要包括Q-learning和SARSA方法,其中根据Q值更新受影响的步长lambda,有Q-learning(lambda)和SARSA(lambda)。
注意:这里的Q-learning是off-policy算法,SARSA是on-policy算法。
Q-learning methods

SARSA methods

超参数分析




Q-learning/SARSA(lambda) methods

Sarsa 是说到做到型, 所以我们也叫他 on-policy, 在线学习, 学着自己在做的事情.Sarsa相当保守,他会选择离危险远远的,拿到宝藏是次要的, 保住自己的小命才是王道. 这就是使用 Sarsa 方法的不同之处.
Q learning 是说到但并不一定做到,所以它也叫作 Off-policy,离线学习.而因为有了 maxQ,Q-learning 也是一个特别勇敢的算法.永远都会选择最近的一条通往成功的道路, 不管这条路会有多危险.




注意lambda是0时,是单步更新,lambda是1时,是回合更新,lambda在0-1之间时,是成一个衰减趋势,离更新近的权重大,远的步权重小。
总结

DP、MC、TD三种方法对比:
1、DP基于模型; MC、TD基于无模型
2、DP采用bootstrapping(自举), MC采用采样,TD采用bootstrapping+采样
3、DP用后继状态的值函数估计当前值函数,MC利用经验平均估计状态的值函数,TD利用后继状态的值函数估计当前值函数
4、MC和TD都是利用样本估计值函数,其中MC为无偏估计,TD为有偏估计
5、最明显的就是下图的值函数的计算方法的不同





(1)不断试错
(2)看重长期回报
QA
参考资料
1、 https://blog.csdn.net/qq_30615903/article/details/80746553
2、 https://www.lizenghai.com/archives/20955.html
3、Reinforcement learning:An Introduction
4、视频课程
5、…………待添加
第二章
本章主要从Deep Reinforcement learning(DRL)基本概念出发,介绍深度强化学习的一些经典算法并辅以公式推导和程序实现。
DRL基本概念
传统的强化学习局限于动作空间和样本空间都很小,且一般是离散的情境下。然而比较复杂的、更加接近实际情况的任务则往往有着很大的状态空间和连续的动作空间。当输入数据为图像,声音时,往往具有很高维度,传统的强化学习很难处理,深度强化学习就是把深度学习对于的高维输入与强化学习结合起来。
DRL 经典算法
2013和2015年DeepMind的Deep Q Network(DQN)可谓是将两者成功结合的开端,它用一个深度网络代表价值函数,依据强化学习中的Q-Learning,为深度网络提供目标值,对网络不断更新直至收敛, 后续还有很多基于DQN的改进版本。但是DQN主要用于解决离散动作空间的问题,无法解决高维连续动作空间,而PG不仅可以用于解决高维连续动作空间,也可以解决离散动作空间问题。同时将PG和值函数两者的优势相结合得到的Actor-Critic框架系列方法性能得到进一步提升。
DDPG可以学习随机策略和连续动作,原始的DQN则无法学习随机策略和连续动作。
随机策略(非确定性策略)vs确定性策略
那么什么是策略呢? 通常情况下被定义为是从状态到行为的一个映射,直白说就是每个状态下指定一个动作概率,这个可以是确定性的(一个确定动作),也可以是不确定性的。
策略是一个战略方针,不是具体的战术动作,例如”敌进我退敌驻我扰敌疲我打敌退我追”就是一个策略,具体的战术动作需要根据当前所处的状态决定;


离散动作vs连续动作


DRL Model-free Methods
下面介绍的DQN系列算法、DDPG系列算法和AC系列算法属于model-free的范畴,即不需要对环境建模,主要通过与环境交互获取抽样样本进行模型的训练。
Deep Q-learning Network(DQN)
下图直观展示DQN算法训练后的吃豆豆的游戏agent。
作为深度强化学习领域的重要开创性工作,DQN的出现引发了众多研究团队的关注。在文献[1]中,介绍了DQN早期的主要改进工作,包括大规模分布式DQN[14]、双重DQN[15]、带优先级经验回放的DQN[16]、竞争架构DQN[17]、引导DQN[18]以及异步DQN[19]等。这些工作从不同角度改进DQN的性能。
此后,研究人员又陆续提出了一些DQN的重要扩展,继续完善DQN算法。Zhao等基于在策略(on-policy)强化学习,提出了深度SARSA(state-action-reward-state-action)算法[20]。实验证明在一些Atari视频游戏上,深度SARSA算法的性能要优于DQN。Anschel等提出了平均DQN,通过取Q值的期望以降低目标值函数的方差,改善了深度强化学习算法的不稳定性[21]。实验结果表明,平均DQN在ALE测试平台上的效果要优于DQN和双重DQN。He等在DQN的基础上提出一种约束优化算法来保证策略最优和奖赏信号快速传播[22]。该算法极大提高了DQN的训练速度,在ALE平台上经过一天训练就达到了DQN和双重DQN经过十天训练的效果。作为DQN的一种变体,分类DQN算法从分布式的角度分析深度强化学习[23]。与传统深度强化学习算法中选取累积奖赏的期望不同,分类DQN将奖赏看作一个近似分布,并且使用贝尔曼等式学习这个近似分布。分类DQN算法在Atari视频游戏上的平均表现要优于大部分基准算法。深度强化学习中参数的噪声可以帮助算法更有效地探索周围的环境,加入参数噪声的训练算法可以大幅提升模型的效果,并且能更快地教会智能体执行任务。噪声DQN在动作空间中借助噪声注入进行探索性行为,结果表明带有参数噪声的深度强化学习将比分别带有动作空间参数和进化策略的传统强化学习效率更高[24]。彩虹(Rainbow)将各类DQN的算法优势集成在一体,取得目前最优的算法性能,视为DQN算法的集大成者[25]。DQN算法及其主要扩展如下图所示:
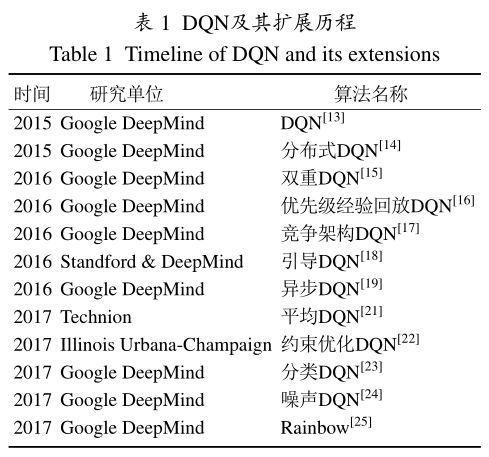
DQN
Double DQN
Prioritised replay
Dueling DQN
RainBow
Deep Deterministic Policy Gradient(DDPG)
基于值函数的深度强化学习主要应用于离散动作空间的任务。面对连续动作空间的任务,基于策略梯度的深度强化学习算法能获得更好的决策效果。
==分类:在策略/离策略梯度;随机/确定性策略梯度;==
目前的大部分actor-critic算法都是采用在策略的强化学习算法。这意味着无论使用何种策略进行学习,critic部分都需要根据当前actor的输出作用于环境产生的反馈信号才能学习。因此,在策略类型的actor-critic算法是无法使用类似于经验回放的技术提升学习效率的,也由此带来训练的不稳定和难以收敛性。Lillicrap等提出的深度确定性策略梯度算法(deep deterministic policy gradient,DDPG),将DQN算法在离散控制任务上的成功经验应用到连续控制任务的研究[30]。DDPG是无模型、离策略(offpolicy)的actor-critic算法,使用深度神经网络作为逼近器,将**深度学习和确定性策略梯度算法有效地结合在一起。DDPG源于确定性策略梯度(determinist policy gradient,DPG)算法[31]**。确定性策略记为πθ(s),表示状态S和动作A在参数θ的策略作用下得到S7→A。期望奖赏J(π)如下所示:






Policy gradient
Stochastic policy gradient (SPG) vs determinist policy gradient (DPG)
DDPG
Trust region policy optimization (TRPO)
PPO
Actor Critic Series Method(AC)

AC
A2C
A3C
UNREAL
DRL Model-based Methods
World Model
PlaNet
总结


QA
参考资料
第三章
Environmental interaction framework
gym只支持linux,Tkinter可以支持win/linux
OpenAI gym
Tkinter (可学), 你可以自己用它来编写模拟环境
AlphaGo Series


